
Data documentation
To make sure that you understand your data and that your data is understandable to other members of the research team or external users, you should add documentation and metadata (information about the data) to any datasets you create.

Why it is necessary to document research data
Datasets should contain machine-readable data. However, without further description of the research data, the dataset may be unrecognisable and incomprehensible. But to follow the FAIR principles and good practice of research, any data should be interpretable by any researcher who would like to access it. A description of the research data, or data documentation, must be prepared and attached to any research dataset created and published in a data repository.
During data collection, you may remember what all your classification systems mean, but it is quite probable you will not be able to recall all file names or codes for data categories after a few years from conducting the research. Adequate documentation that explains the codes you used and how you organized your data eliminates this possibility and gives another chance to use or re-use the data.
By documenting the research data, you ensure:
- wider understanding of your findings
- possibility to verify your results
- high-quality review process of your submitted publication
- the possibility to replicate of your results
- archiving of your data for access and reuse.
Good documentation will ensure that all of the above options are possible no matter what system or software is used.
When and how should I create documentation and metadata?
You should document your data from the very beginning of the research project and continue to add information as the project progresses. Documentation procedures should be described in the Data Management Plan. Documentation helps you understand the structure and content of the data itself, as well as the context in which the data was created.
The documentation of the data takes place at several levels:
-
Documentation at the variable level
This documentation can be included in the data itself or in the document, e.g., in a specified location in the file. Examples of variable-level documentation may include variable names and definitions, units of measure, information on codes, missing values, etc.
-
Documentation at file or dataset level
Explains how all the files that make up a dataset relate to each other, what format they are in, or whether certain files are intended to replace other files, etc.
-
Documentation at the project level
Explains the objectives of the study, what the research questions/hypotheses are, what methodologies are used, what tools and measures are used, etc. This information is included in separate files attached to the data to provide context, explanation or guidance for the use or reuse of the data. Examples of project-level documentation include working papers, lab books, questionnaires, interview guides, final project reports, and publications.
Data should be documented at all stages of the research data lifecycle. Detailed documentation promotes reproducibility and research integrity. Documentation also includes metadata.
Metadata
Metadata (= data about data) describes data in a standardised format and is intended for machine reading. Properly using metadata allows research data to be found and reused. For a better overview, the National Technical Library's General Recommendation for Metadata Description of Research Outputs and Research Data summarises basic information about metadata description.
The metadata in the publication and data repository is inserted by the scientist when the publication/research data is deposited. In addition, it is recommended to add discipline-specific information that is relevant to the scientific field.
Whether you publish a record in a data or publication repository, metadata records must be publicly available and machine-readable, following FAIR principles, and must include at a minimum the following information:

The records in the Open Repository of Research and Development Results of Mendel University in Brno contain not only the minimum metadata: repozitar.mendelu.cz but also the OpenAIRE metadata requirements. The publication metadata is automatically transferred to the repository from the OBD system.
Metadata is often created according to subject standards, you can search for metadata standards according to your subject: https://www.dcc.ac.uk/guidance/standards/metadata.
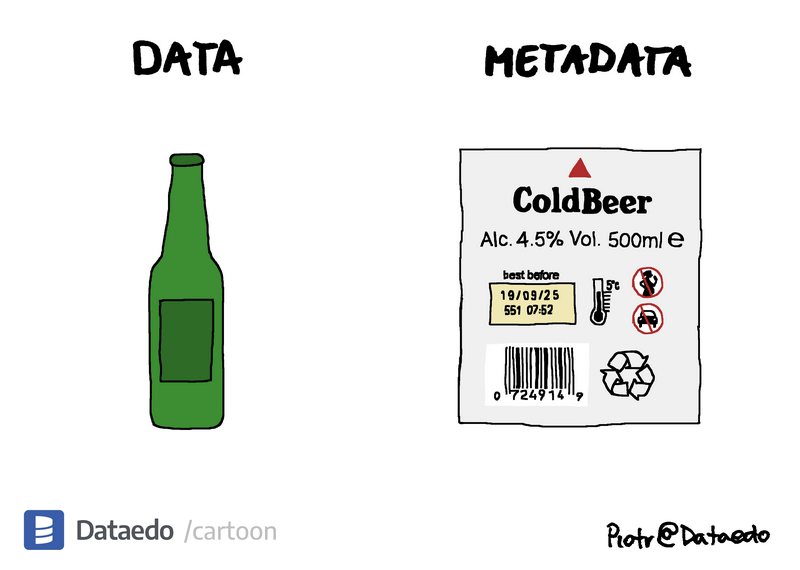
Dataedo. 2022. Data vs Metadata. [cit. 24-02-28]. https://dataedo.com/cartoon/data-vs-metadata-8.
Metadata Standard
A metadata standard is a set of predefined guidelines that specify the structure and format of metadata and ensure consistency in the description and management of data. Simply put, metadata standards act as grammatical rules, helping to set a consistent set of guidelines for creating metadata.
There are many metadata standards, among the most widely used is Dublin Core, which is often used in databases and search engines. Dublin Core is a set of 15 basic metadata elements that you should use to describe your dataset or file.
| Metadata element | Definition of metadata element |
| Title | A name given to a file/dataset |
| Creator | An entity primarily responsible for making the content of a file/dataset |
| Subject | A topic of the content of a file/dataset |
| Description | An account of the content of the file/dataset |
| Publisher | An entity responsible for making the file/dataset available |
| Contributor | An entity responsible for making contributions to the content of a file/dataset |
| Date | A date of an event in the lifecycle of a file/dataset |
| Type | The nature or genre of the content of a file/dataset |
| Format | The physical or digital format of a file/dataset |
| Identifier | An unambiguous reference to the file/dataset within a given context |
| Source | A reference to another resource from which a file/dataset is derived |
| Language | A language of the content of a file/dataset |
| Relation | A reference to a related file/dataset |
| Coverage | The extent or scope of the content of a file/dataset |
| Rights | Information about rights held in and over the file/dataset |
National Centre for Information Support of Research, Development, and Innovation. 2024. Workshop lecture – Introduction to a Research Data Management…and how not to get overwhelmed by data. [cit. 24-05-23]. https://moodle.techlib.cz/pluginfile.php/8842/mod_resource/content/6/24-03-27_RDM%20at%20NTK_v5_moodle.pdf
Where to document your data?
A ReadMe is a text file that is used to document research data - it explains the contents of a research project folder or published dataset. It usually describes the background, context and collection process of the research data and is usually written in plain text format (.txt) so that anyone can open and read it. The ReadMe file is uploaded with the dataset to a data repository in order to understand the meaning of the research project.
When publishing or sharing data, it is useful to provide a ReadMe file so that other people know what the datasets contain, which parts of the research they relate to, how specific files are related, how the data was generated, how the datasets were processed or transformed, and whether there are any restrictions on who can view or access the data.
What to include in the ReadMe file
There are no set rules for what to include in a ReadMe, but in general, you should include all the information necessary for understanding and reusing the data. For example:
There are several options for data documentation: readme files, electronic lab journals, or GitHub. Which option you choose is up to you, the important thing is that the data is clearly described and the documentation is always accessible along with the data.
 The Turning Way. 2024. Fig. 54 Illustration about managing files in a repository. In: Data Storage and Organization. [cit.24 - 02 - 28]. https://the-turing-way.netlify.app/reproducible-research/rdm/rdm-storage
The Turning Way. 2024. Fig. 54 Illustration about managing files in a repository. In: Data Storage and Organization. [cit.24 - 02 - 28]. https://the-turing-way.netlify.app/reproducible-research/rdm/rdm-storage
- Instructions on how to create a ReadMe file.
- TIP: by describing your data in English, your data can be reusable for foreign researchers.
Electronic lab journals
Your data can be also documented through electronic lab journals. Examples include:
- eLabJournal
- Kadi4Mat – combines a data management environment and a laboratory journal
- eLabFTW – open source
- openBIS – data management environment and lab journal
- Jupyter Lab – a tool for creating DMPs and also for sharing data, can link data from Jupyter to openBIS
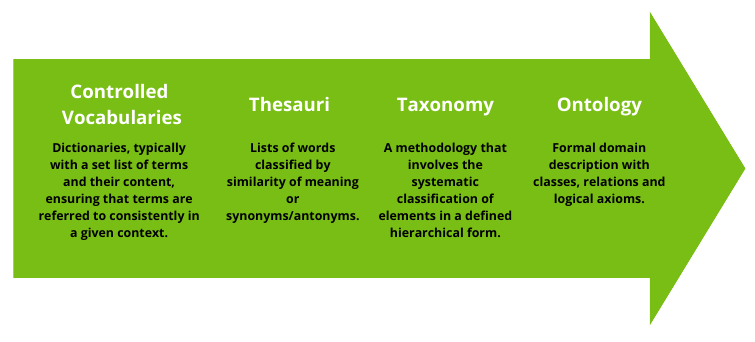
Ontologies, taxonomies, controlled vocabularies, thesauri
The purpose of using ontologies or controlled vocabularies is to facilitate the understanding of the dataset but also to support data interoperability or easier discovery. Ontologies define relationships between concepts from specific domains of human knowledge. Each ontology is based on a precise and formal definition of concepts and relationships. The most common type of ontology incorporates a taxonomy. A taxonomy defines classes and subclasses of objects and their relationships and plays a role in research data management because object classification helps researchers navigate a given dataset. Controlled vocabularies and thesauri then help to ensure consistency in describing research data across disciplines.
As an example, AGROVOC is a controlled vocabulary covering research areas including food, nutrition, agriculture, fisheries, forestry, environment, etc. AGROVOC contains more than 41,000 terms available in up to 42 languages.
Controlled vocabularies, ontologies, thesauri and taxonomies exist not only for the natural sciences but also for the humanities and social sciences. As an example, scholars focusing on European studies can use EuroVoc, a multilingual, multidisciplinary thesaurus covering the activities of the EU, in particular the European Parliament. It contains terms in the 23 official EU languages and in the three languages of the EU candidate countries.
- A search engine for ontologies and controlled vocabularies for specific research domains: https://fairsharing.org/search?fairsharingRegistry=Standard
References
- Národní technická knihovna. 2022. Obecné doporučení pro metadatový popis výsledků výzkumu (zejména publikací a dat) [cit. 24-03-11]. https://repozitar.techlib.cz/server/api/core/bitstreams/8cad20c6-14de-4429-b8ed-74f514c052da/content
- University of Sussex. 2024. Documentation and metadata [cit. 24-02-28]. https://www.sussex.ac.uk/library/researchdatamanagement/organise/documentationandmetadata
- ResearchHub. 2024. Describing research data with a README. [cit. 24-02-28]. https://www.gla.ac.uk/media/Media_359359_smxx.pdf