
Data organization
To promote the reusability of your research data, but also to make your work easier for yourself and your colleagues, you need to develop rules for organising your research data. Establishing a logical and consistent system for organizing your datasets will enable you and others to find and use them efficiently, help maintain data integrity, or enhance the reputation of your scientific work.
Research data organisation has 4 main parts:
- File naming rules
- Folder naming rules
- Rules for versioning
- Saving data in sustainable formats
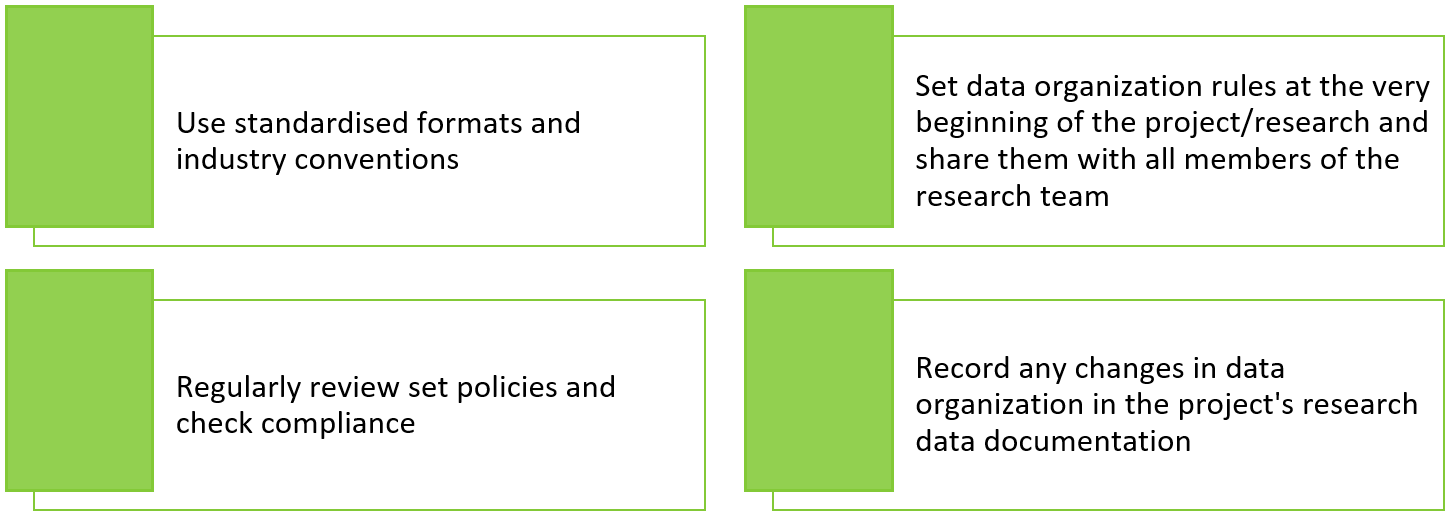
When considering how to organise your data, keep the following principles in mind:
File naming system
The file naming system makes it easier to find your data and navigate through them during and after research. A well-configured file naming system should ensure:
- The ability to see the contents of a file without opening it
- Finding and identifying the file even if it is no longer in the original folder
- Browsing through long lists of files to keep track of them or to check if any are missing
- Managing files even if they are all stored in one central folder or directory

Good file naming practice

Folder naming system
There is no one right or universal way to set up a folder naming system, however, the important thing is that the structure you decide to use is logical, readable, and makes sense for the purpose. For example, you can organize your folders:
- by task (e.g. work package, experiment, documentation) li>
- by a significant defining characteristic (e.g. location, sample number, company name, experiment type)
- data type (e.g. raw, processed, final)
- by measurement method (e.g. for larger projects, with multiple activities and using multiple measurement methods or sample conditioning techniques)
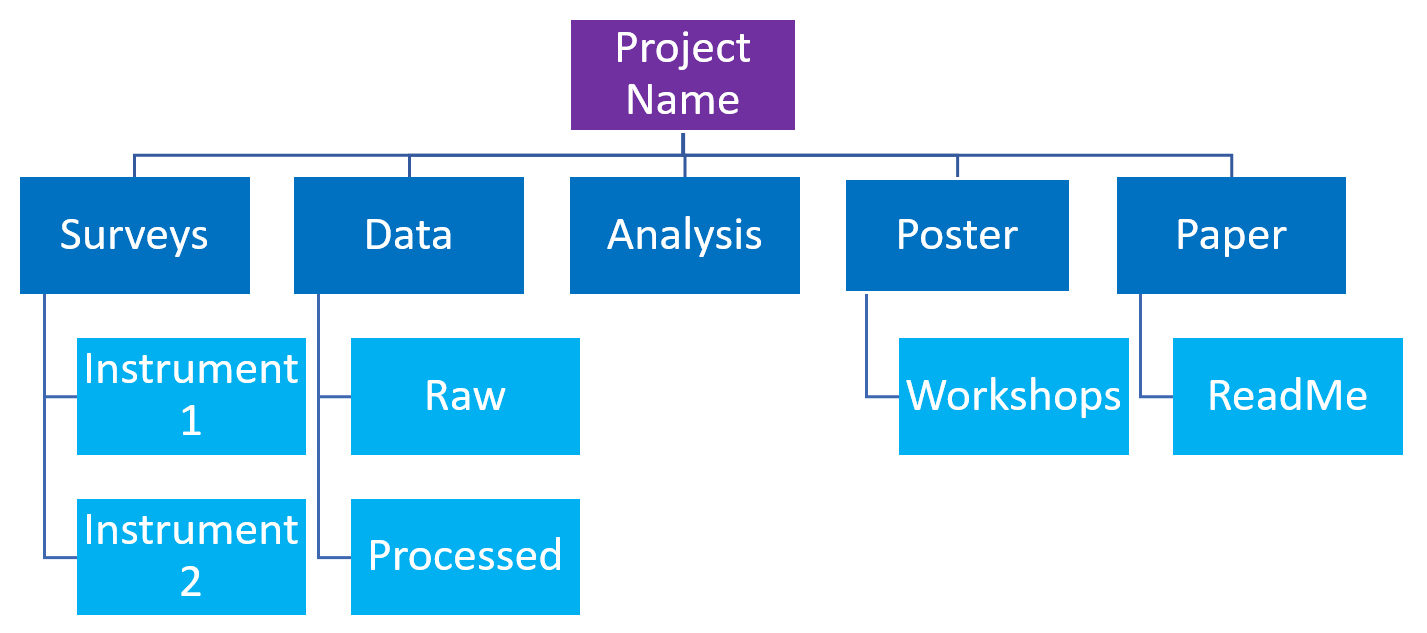
University of Ottawa. 2024. File naming and organization of data. [cit. 24-02-28]. https://www.uottawa.ca/library/research-data-management/data-management-plan/file-naming-organization-data
Don't let the folder structure get too complicated, and avoid too many layers in the hierarchy (ideally no more than four). Confidential information and sensitive data, such as participant records, should be stored in separate folders with appropriate access controls. Raw data and milestone versions of documents should be stored as read-only files, ideally in separate folders.
Good folder naming practice

File versioning and version control
File versioning is a system for recording changes to a file or set of files over time. Versioning plays a big role whenever you work in a research group where you all share and edit files. Uncontrolled versions of files edited by different people can easily spread, which can cause chaos in the research data and the transformations the data has gone through. In the worst-case scenario, this can compromise the integrity of the data- for example, if the raw data file is overwritten.
There are a few simple things you can do to implement effective version control. It is not necessary to always use all of the following tips, it will highly depend on the nature of your research and the processes that the data undergoes.

Versioning in practice
Version control can be provided by adding a number to the end of the file name. Each document is then numbered sequentially from v0.1, v0.2, v0.3... until a new, final version of the document is created. Then eventually the file should be named v1.0. If the v1.0 version is to be revised, drafts would be again numbered as v1.1, v1.2, etc. until the v2.0 version is completed.
All versioning rules need to be set at the beginning of the research or project so that everyone involved knows how to handle the versions and how to write down any changes.
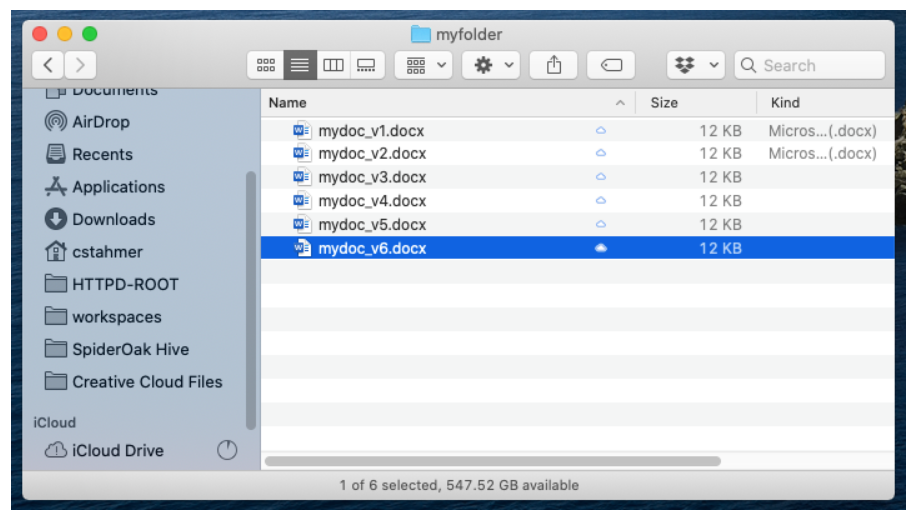
UC Davis Data Lab. 2024. What is Version Control? [cit. 24-02-28]. https://ucdavisdatalab.github.io/workshop_introduction_to_version_control/version-control.html
Example of a file version management table
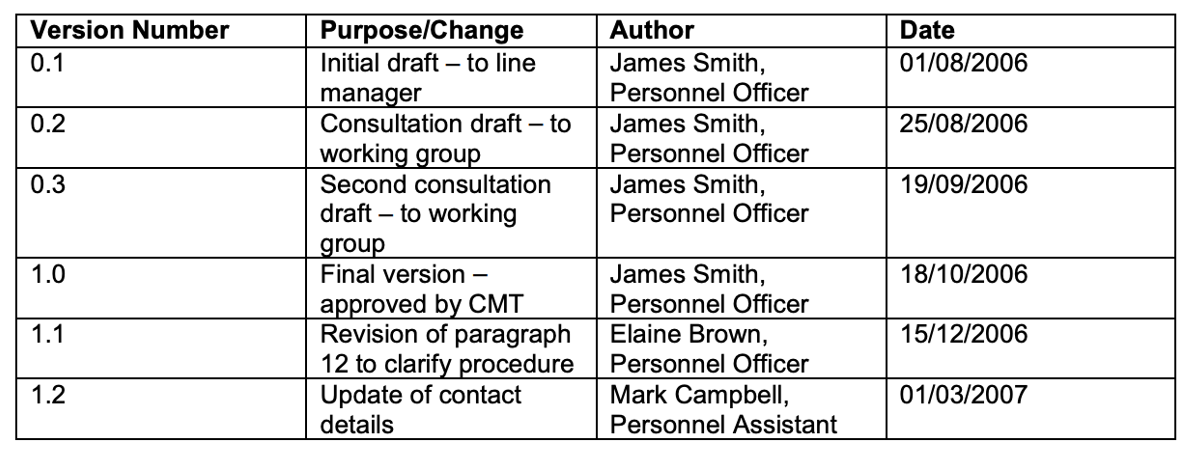
University of Glassgow. 2024. Good Practice Guidance. Version Control. [cit. 24-02-28]. https://www.gla.ac.uk/media/Media_359359_smxx.pdf
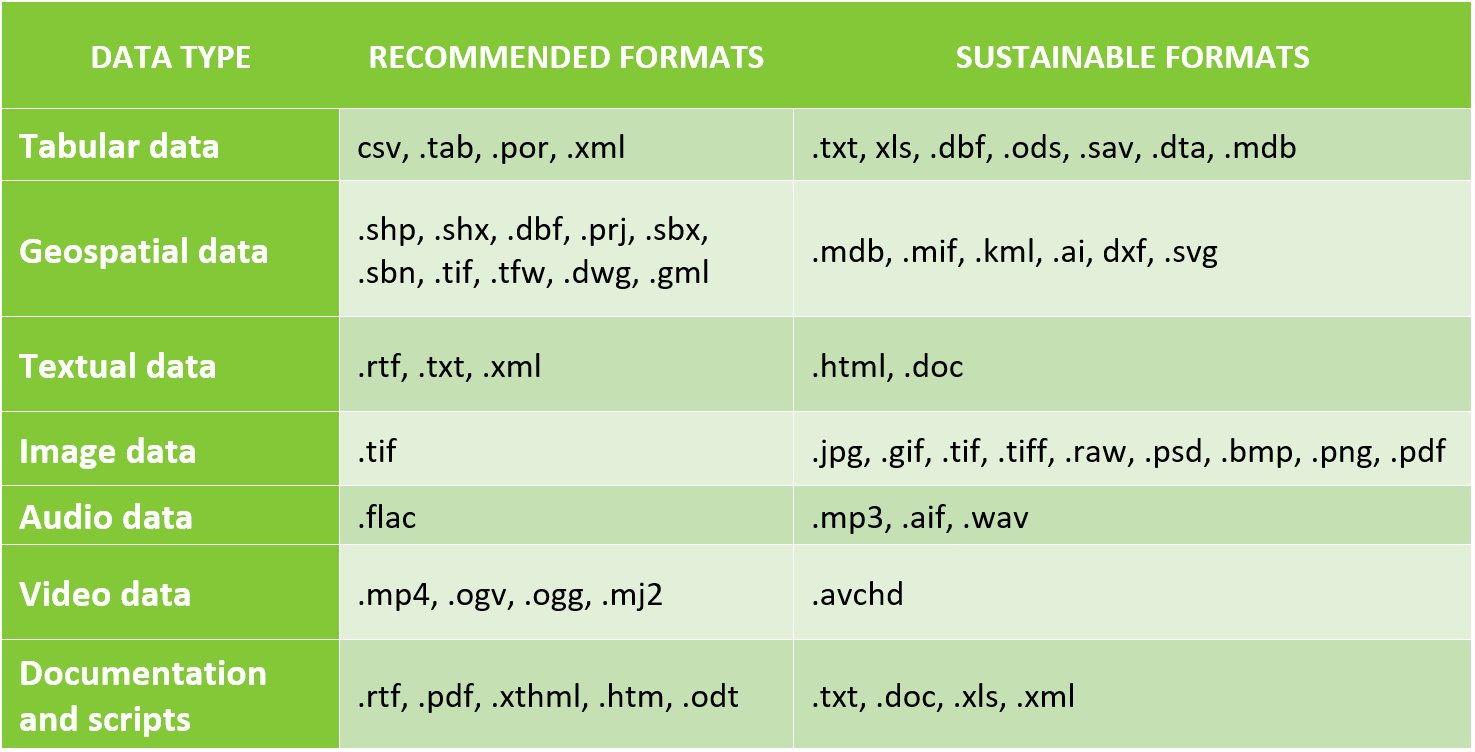
Saving data in sustainable formats
Specific file formats can help ensure long-term data access and sharing. Once you have completed the analysis of your research data using the specific types of software and formats that are most appropriate for your planned analysis, consider converting your files to stable open formats for long-term storage. These formats are typically:
- Interoperable between different platforms and applications
- Fully public and available without licensing fees
- Standard for the field or commonly used by the research community
- Contain data descriptions (metadata)
- Adhere to an open, documented standard
References
- Huridocs.org. 2024. File Naming Conventions. [cit. 24-02-28]. https://huridocs.org/resource-library/organising-a-collection-of-human-rights-information/file-naming-conventions
- UC Davis Data Lab. 2024. Version Control. [cit. 24-02-28]. https://ucdavisdatalab.github.io/workshop_introduction_to_version_control/version-control.html
- University of Glasgow. 2024. Good Practice Guidance. Version Control. [cit. 24-02-28]. https://www.gla.ac.uk/media/Media_359359_smxx.pdf
- University of Ottawa. 2024. File naming and organization of data. [cit. 24-02-28]. https://www.uottawa.ca/library/research-data-management/data-management-plan/file-naming-organization-data
- University of Reading. 2024. File formats. [cit. 24-02-28]. https://www.reading.ac.uk/research-services/research-data-management/managing-your-data/file-formats
- University of Reading. 2024. Organising your data. [cit. 24-02-28].https://www.reading.ac.uk/research-services/research-data-management/managing-your-data/organising-your-data