
Kategorizace dat
Kategorizace dat umožňuje rozlišit typy výzkumných dat podle jejich citlivosti a hodnoty pro výzkum/organizaci v případě jejich změny, zničení, popřípadě krádeže. Kategorizace dat vědci dále pomáhá pochopit hodnotu zpracovávaných výzkumných dat a případně určit jaké kontrolní a bezpečnostní opatření je potřeba zvést, aby se zabránilo potenciálním rizikům.
Výzkumná data je možné rozdělit do čtyř kategorií právě podle jejich citlivosti. Zařazení dat do různých kategorií pak má mít vliv na to, kde můžete data ukládat, jak je zabezpečit, ale také na to, jaké jsou možnosti uložení dat po skončení výzkumu v datovém repozitáři.
| VEŘEJNÁ DATA | |
| Data zpřístupnitelná bez jakýchkoliv omezení komukoliv.
Příkladem jsou data veřejně vystavená na internetu. Jejich zveřejnění nikoho neohrožuje/nepoškozuje. |
|
| Vhodná úložiště: Fyzická úložiště ; Cloudová řešení (externí) ; Síťové disky (interní) ; Cloudová řešení (smluvní) | |
| Vložení do datového repozitáře bez omezení | |
| INTERNÍ DATA | |
| Nevyžadují zvláštní regulaci nebo ochranu ze zákona/ dle smlouvy.
Data určená jen pro vnitřní potřebu organizace nebo skupiny. Zpřístupnění mimo danou skupinu nezpůsobí přímou škodu (finanční, morální, právní). |
|
| Vhodná úložiště: Fyzická úložiště ; Síťové disky (interní) ; Cloudová řešení (smluvní) | |
| Vložení do datového repozitáře je po zvážení možné | |
| DISKRÉTNÍ DATA | |
| Data vyžadující regulaci nebo ochranu, typicky jsou data chráněná ze zákona nebo na základě nějaké smlouvy/licence.
Data určená výhradně pro vnitřní potřebu přesně definované skupiny osob, např. zaměstnanec a jeho nadřízený, pracovník HR oddělení a uchazeč o zaměstnání, skupina správců IT systému s administrátorskými právy k němu. Jedná se o osobní údaje, data spadající pod obchodní tajemství. Zpřístupnění mimo danou skupinu osob velmi pravděpodobně způsobí škodu (finanční, morální, právní...). |
|
| Vhodná úložiště: Síťové disky (interní) ; Cloudová řešení (smluvní) | |
| Vložení do datového repozitáře nelze bez omezení* | |
| CITLIVÁ DATA | |
| Vyžadují ze své povahy zvláštní regulaci nebo obzvláštní ochranu, typicky jsou data přísně chráněná ze zákona nebo na základě smlouvy/licence.
Data určená striktně jen pro vnitřní potřebu přesně definované skupiny osob, například zdravotník a pacient, řešitelé projektu s bezpečnostním prověřením určité úrovně. Jedná se o velmi cenná data spadající pod obchodní tajemství, citlivé osobní údaje. Zpřístupnění mimo danou skupinu oprávněných osob způsobí škodu (finanční, morální, právní) velkého rozsahu se závažnými následky. |
|
| Vhodná úložiště: Síťové disky (interní) ; Cloudová řešení (smluvní) | |
| Vložení do datového repozitáře nelze bez omezení a dalších opatření* | |
Obsah stránky byl inspirován stránkou Masarykovy univerzity: Doporučení pro užívání úložišť
*Některé kategorie výzkumných dat nemohou být po dokončení výzkumu zveřejněny bez omezení, a to právě s ohledem na jejich charakter. To se týče především kategorie citlivých dat. Vědci by měli před plánovaným zveřejněním citlivých dat přijmout další opatření, v souladu s příslušnými bezpečnostními, etickými a právními předpisy.
Doporučená opatření pro nakládání s citlivými daty během a po skončení výzkumu:
1. Informovaný souhlas
Před zahájením výzkumu, a to i v okamžiku podání projektu (grantové žádosti), je nutné nastavit, jakým způsobem mohou být generovaná nebo sesbíraná citlivá data sdílena. V ideálním případě byste měli poskytnout vaše výzkumné záměry a plán pro sdílení citlivých dat po ukončení projektu institucionální kontrolní komisi pro etické otázky ve výzkumu. Včasná nastavení plánů pro ukládání a sdílení citlivých dat je nutné také pro informování případných účastníků o sdílení citlivých dat, za účelem získání jejich informovaného souhlasu.
Už při oslovení účastníků výzkumu byste měli všechny participanty seznámit výzkumným tématem, ale také s plánem pro uchování a sdílení citlivých dat o jejich osobě. Souhlas je nutné pořídit v písemné nebo alespoň ústní formě (např. zvukový soubor) a musí být udělen svobodně – není možné například poskytnout formulář s předem zaškrtnutými políčky. Účastníci také musí mít možnost z výzkumu vystoupit v případě, že nesouhlasí se způsobem uchování a sdílení svých dat.
2. Anonymizace
Anonymizací se ze souboru dat odstraní identifikační informace. Jedná se o opatření pro zajištění ochrany soukromí účastníků výzkumu a snížení pravděpodobnosti opětovné identifikace. Přestože anonymizace odstraňuje ze souboru dat identifikovatelné informace, měli byste tyto postupy použít pouze v případě, že jste k tomu od účastníků získali informovaný souhlas.
Při zvažování anonymizace datových souborů budete pravděpodobně muset odstranit přímé i nepřímé identifikátory. Přímý identifikátor, jako je celé jméno, datum narození nebo adresa, jednoznačně identifikuje účastníka výzkumu. Nepřímé identifikátory mohou jednoznačně identifikovat účastníka výzkumu v kombinaci, například etnický původ, pohlaví, místo narození a pracovní pozice. Anonymizační postup bude vždy specifický pro vámi vytvořený soubor dat, proto není možné poskytnout konkrétní návod. V průběhu procesu anonymizace byste ale měli soubory s citlivými daty průběžně kontrolovat, abyste se ujistili, že jste odstranili dostatečné množství informací, aniž byste zničili hodnotu dat.
Mezi hlavní techniky anonymizace dat patří:
- Odstranění proměnných, které nejsou nezbytné pro analýzu nebo nejsou relevantní pro výzkum.
- Zobecnění: snížení specifičnosti informace, například záměna adresy za město.
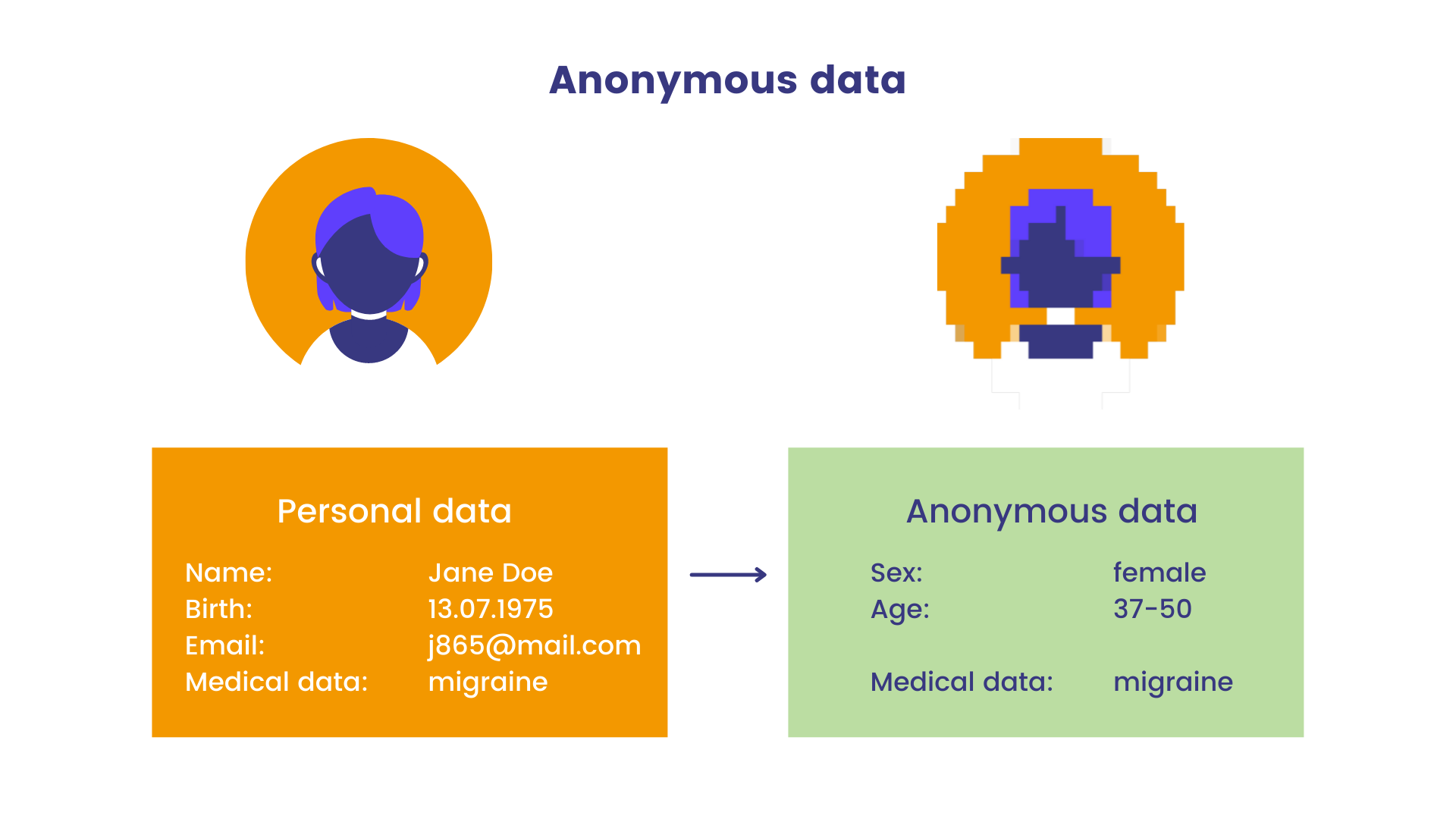
Statice. 2023. Infographics. In: Pseudonymization vs anonymization: differences under the GDPR. [cit. 24-02-27]. https://www.statice.ai/post/pseudonymization-vs-anonymization.
- Pseudonymizace: odkazování na účastníka výzkumu bez použití jeho skutečných dat záměnou jeho jména za jinou vytvořenou verzi.
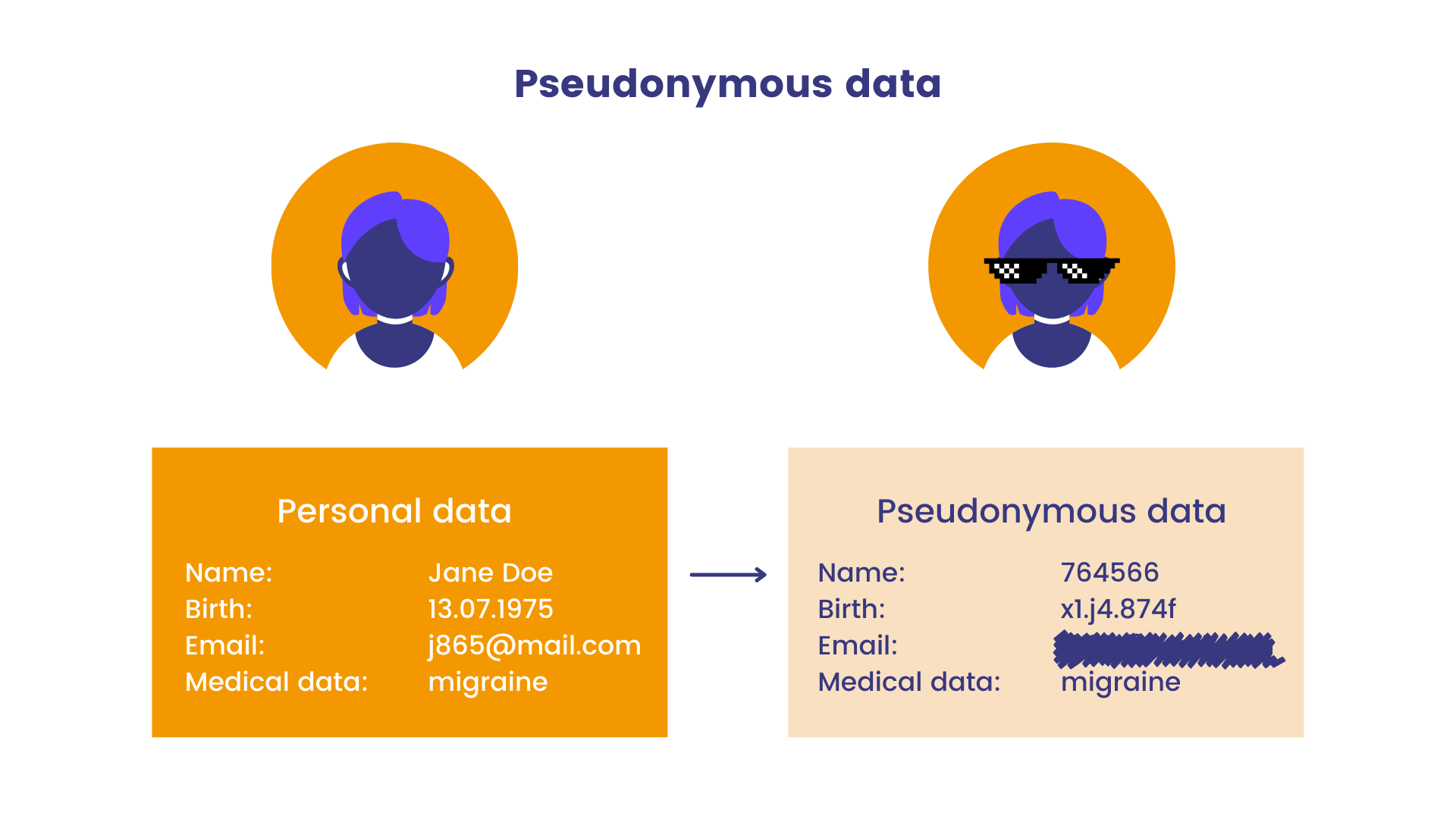
Statice. 2023. Infographics. In: Pseudonymization vs anonymization: differences under the GDPR. [cit. 24-02-27]. https://www.statice.ai/post/pseudonymization-vs-anonymization.
- Vytváření pásem (banding): převzetí specifických informací, jako je věk, a jejich zařazení do rozmezí.
Při anonymizaci jednoho souboru dat může být nutné použít kombinaci těchto postupů. Podobné techniky lze použít pro anonymizaci kvalitativních dat a jakoukoli změnu původního souboru údajů lze označit diakritikou kolem textu, například symboly # nebo @.
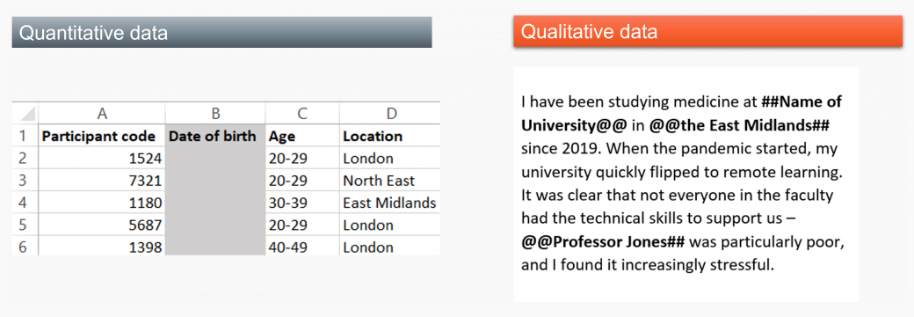
F1000 BlogNetwork. 2019. Sharing sensitive data:key consideration and approaches for safer sharing. [cit. 24-02-27]. https://blog.f1000.com/2023/01/12/safe-sharing-sensitive-human-research-data
3. Řízený přístup
V případech, kdy vaše soubory s citlivými daty není možné plně anonymizovat, nebo kdy by proces anonymizace vedl ke znehodnocení dat a narušení jejich použitelnosti ve výzkumu, je stále možné zpřístupnit a zároveň chránit soukromí účastníků pomocí zveřejnění v repozitáři s řízeným přístupem, ale pouze po získání souhlasu účastníků.
Datová repozitáře s řízeným přístupem poskytují místo, kde mohou výzkumní pracovníci sdílet datové soubory, ale nezveřejňují je otevřeně. Obvykle se místo zveřejnění dat otevřeně sdílí metadatový záznam popisující data a repozitář nastavuje, aby k datům měli přístup pouze schválení uživatelé. Pokud publikujete práci založenou na citlivých datech a vaše datová sada je zveřejněná v datovém repozitáři s řízeným přístupem, můžete pomocí prohlášení o dostupnosti dat popsat, kde se data nacházejí a za jakých podmínek k nim lze přistupovat. Další informace k datovým repozitářům s řízeným přístupem najdete na stránce Datové repozitáře.
Zdroje
- F1000 BlogNetwork: https://blog.f1000.com/2023/01/12/safe-sharing-sensitive-human-research-data
- Evropská komise: https://commission.europa.eu/law/law-topic/data-protection/reform/rules-business-and-organisations/legal-grounds-processing-data/sensitive-data/what-personal-data-considered-sensitive_cs
- Statice: https://www.statice.ai/post/pseudonymization-vs-anonymization